Para la mayoría de las organizaciones, la recopilación y el análisis rápidos de datos son cruciales para agilizar las operaciones, garantizar la seguridad y obtener información oportuna sobre TI y OT. La computación y la gestión de datos rápidas también son de vital importancia para la Industria 4.0, la automatización de la fabricación, los vehículos autónomos y otras aplicaciones intensivas en datos. Las soluciones de computación de borde disponibles hoy en día permiten a las organizaciones capitalizar la Internet de las Cosas (IoT) mediante el despliegue de dispositivos inteligentes en el borde de la red para reducir la latencia y el uso de ancho de banda mediante la gestión de datos donde se generan.
¿Qué es el Edge Computing?
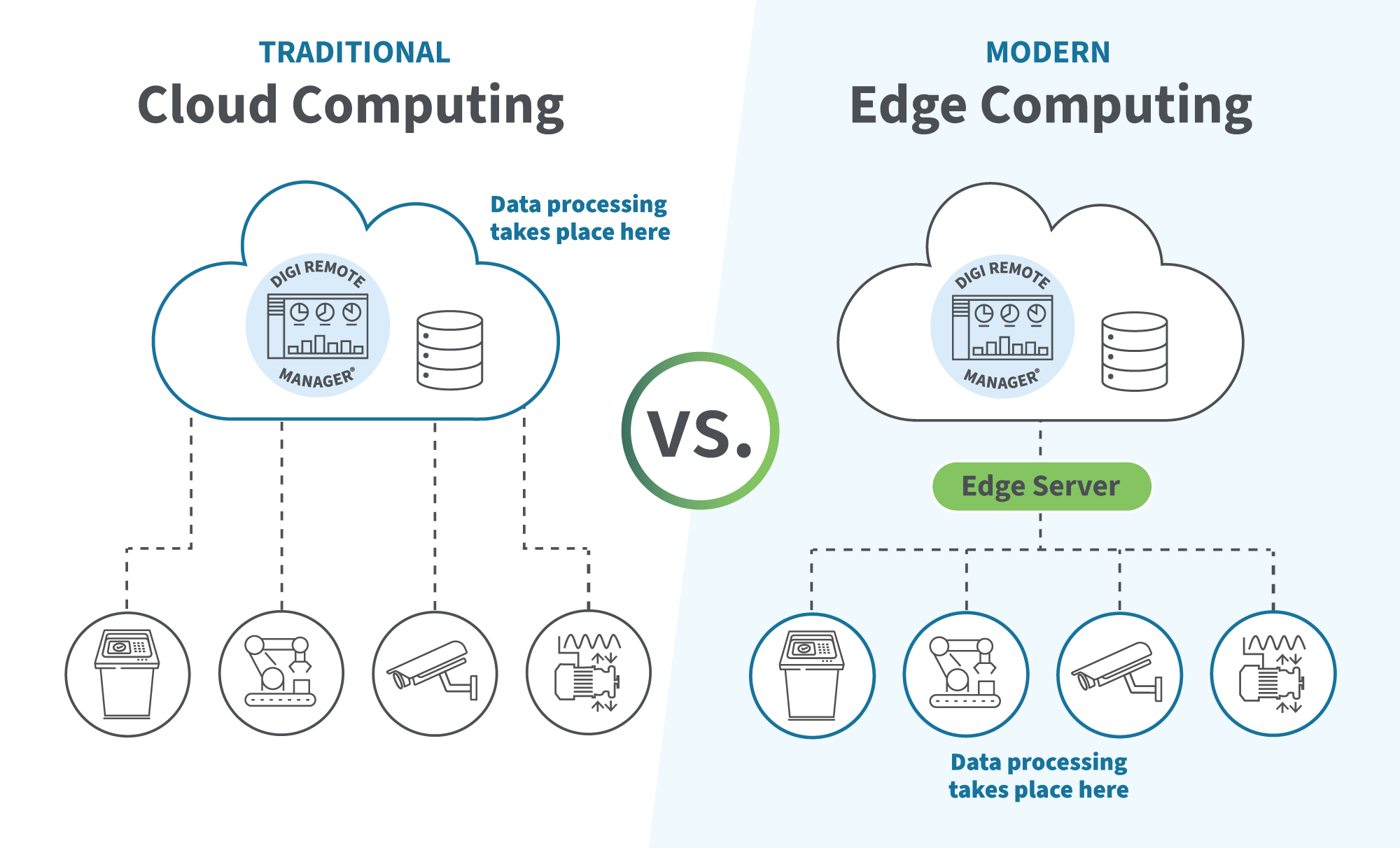
La computación de borde es una arquitectura que utiliza un modelo de computación distribuida para eliminar las ineficiencias en la gestión de datos y reducir la latencia. IoT y los dispositivos móviles dentro del marco distribuido utilizan dispositivos IoT como sistemas integrados, routers celulares y servidores en serie para recopilar y procesar datos en su origen en lugar de transferirlos a un servidor central, centro de datos o solución en la nube para su procesamiento, como sería necesario con un enfoque tradicional de computación en la nube y gestión de datos IoT .
El modelo de edge computing permite a las organizaciones ahorrar ancho de banda, tiempo y dinero. Este modelo aprovecha la potencia de los dispositivos inteligentes de borde, la inteligencia de borde y la conectividad celular como medio para reducir el tráfico entre redes y mejorar la eficiencia. La inteligencia artificial (IA) y el aprendizaje automático (ML) pueden acelerar la velocidad de procesamiento de la arquitecturaIoT realizando análisis de borde, identificando patrones, tomando medidas y enrutando datos.
IoT y Edge Computing
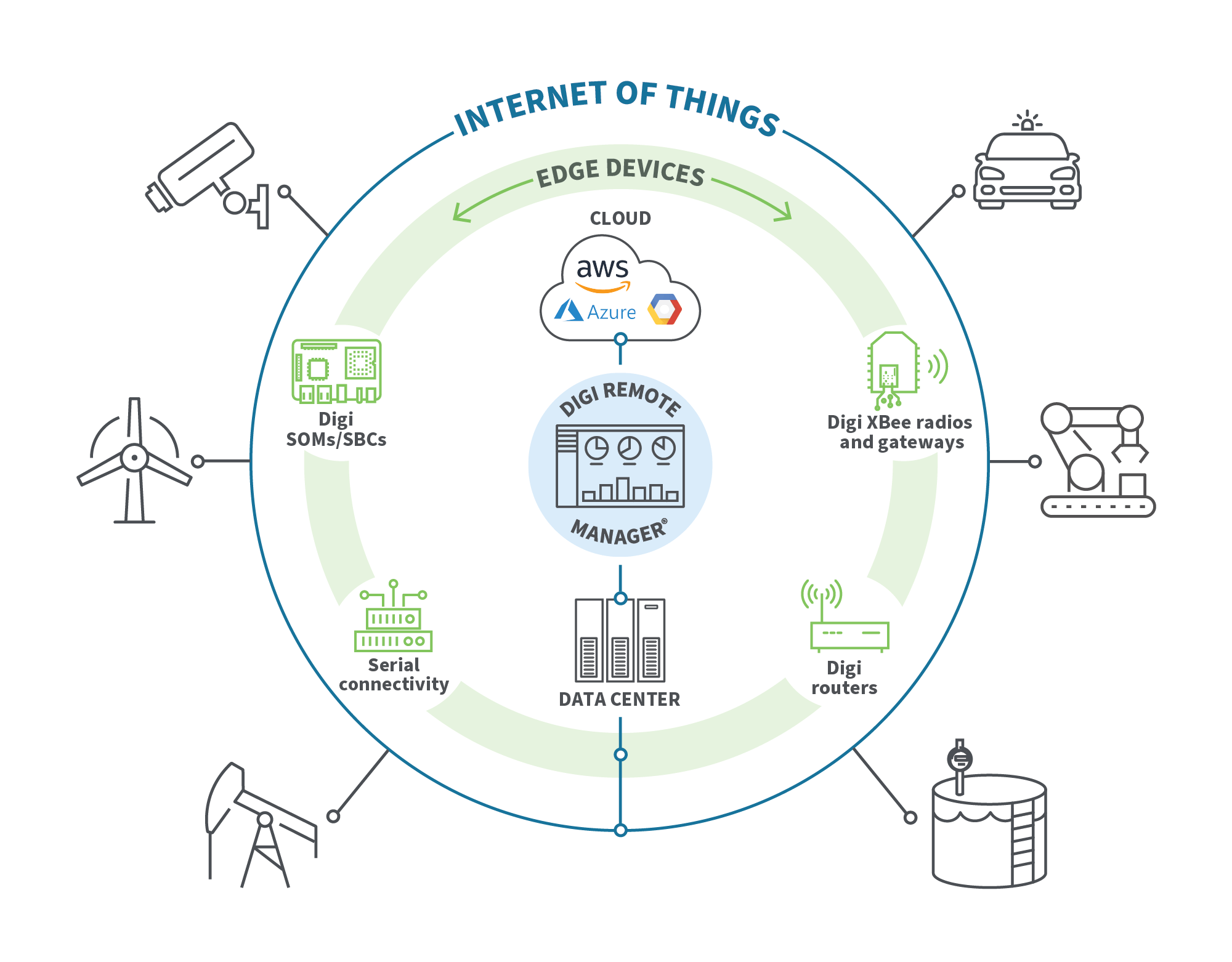
IoT se refiere a una variedad de dispositivos de recogida de datos, que pueden o no procesar datos en el borde. Algunos ejemplos de dispositivos IoT incluyen:
- Monitores de producción
- Ropa sanitaria
- Sensores de movimiento de seguridad
- Sistemas de iluminación inteligentes
- Vehículos autoconducidos
- Controles semafóricos inteligentes
- Sensores de vigilancia ambiental
- Contadores inteligentes
- Dispositivos de seguimiento de flotas
Edge computing en IoT permite a los dispositivos aumentar la eficiencia en el uso de datos y agilizar las operaciones. Cuando se combinan con la tecnología Edge Computing, los dispositivos IoT pueden admitir el procesamiento de datos en tiempo real para mejorar la velocidad de enrutamiento de datos en aplicaciones críticas, ofrecer una mejor gestión del ancho de banda y reducir los costes de datos.
¿Cómo funciona el Edge Computing?
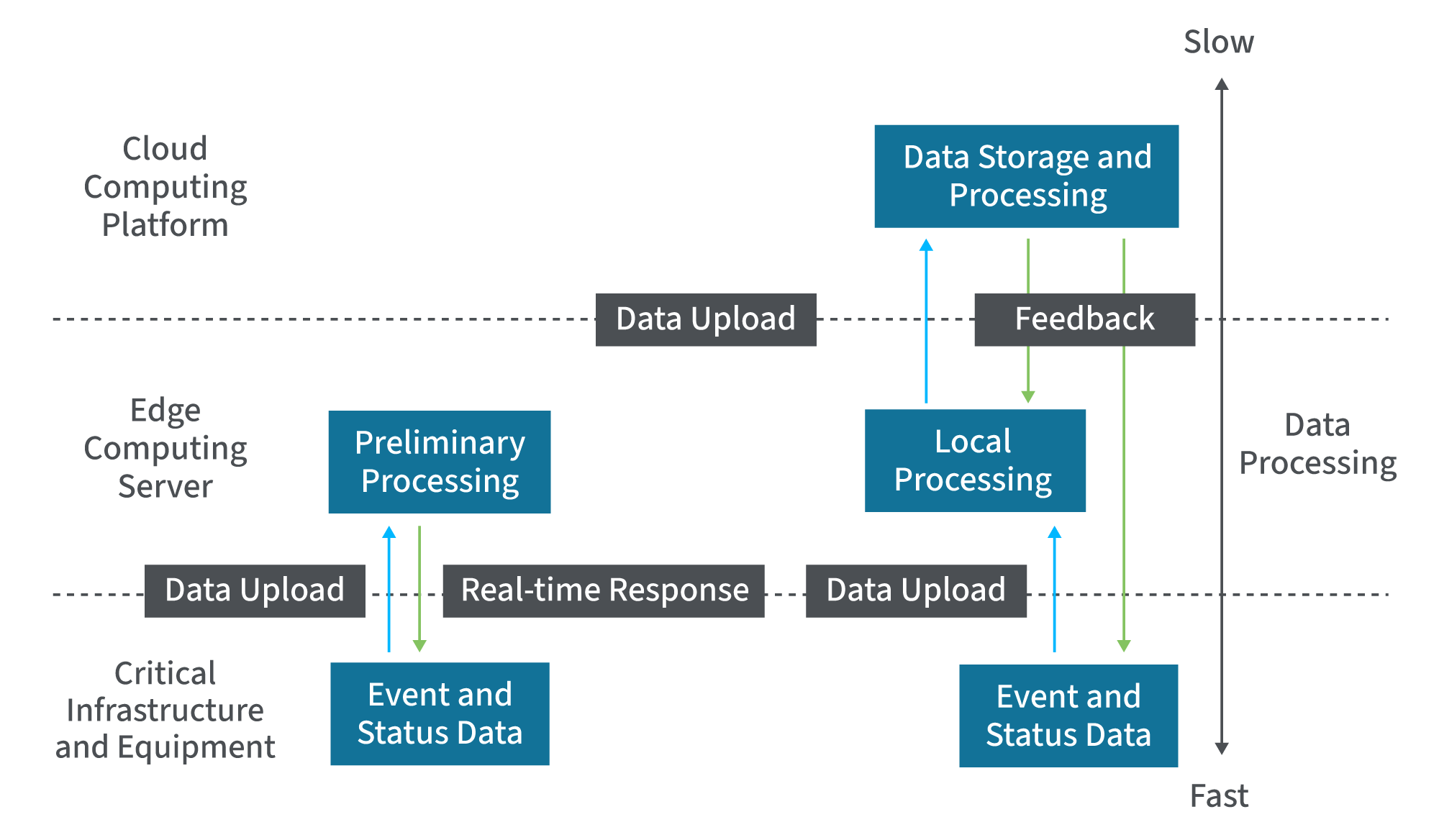
Las soluciones de computación periférica permiten alcanzar una serie de objetivos operativos. La infraestructura de borde puede incluir cámaras, sensores y una serie de dispositivos IoT que realizan el procesamiento de forma inmediata y local, y enrutan sólo datos específicos a servidores centralizados para su posterior análisis, perspectivas operativas o almacenamiento. Los dispositivos periféricos inteligentes también pueden emprender una serie de acciones, desde realizar análisis hasta iniciar informes o solicitudes de servicio, o provocar inmediatamente el cese de la maquinaria o las operaciones por problemas de seguridad.
Tras el procesamiento inicial, los dispositivos de computación de borde determinan qué datos deben transferirse a otros sistemas. Como resultado, la cantidad de datos enviados a través de la red es limitada, garantizando que sólo la información crítica se retransmite a los centros de datos o soluciones en la nube para la inteligencia empresarial. Para hacer posible este sofisticado paradigma de computación periférica, se requiere una combinación de chips de computación periférica, capacidades de procesamiento de dispositivos y herramientas de supervisión y gestión remotas.
Procesamiento de bordes
Los métodos tradicionales de análisis de datos suelen basarse en soluciones de procesamiento centralizado, como centros de datos, soluciones en la nube o servidores. Aunque estos métodos proporcionan suficiente potencia de cálculo, requieren el envío de datos desde dispositivos IoT u otros puntos de recogida a través de la red para su procesamiento. En última instancia, esto genera latencia y requiere un ancho de banda considerable, lo que se traduce en una menor eficiencia.
Con un despliegue de borde, los dispositivos móviles, IoT, y otros dispositivos informáticos de borde tienen capacidad de procesamiento para analizar la información recogida y apoyar la automatización, la toma de decisiones en tiempo real o los ajustes operativos. Para ello se utilizan chips de borde integrados y dispositivos de borde inteligentes, que permiten un procesamiento de borde inmediato allí donde se generan los datos.
Las ventajas del edge computing, comparadas con las del fog computing, son también considerables. Con la informática de niebla, hay una capa de procesamiento entre la capa de borde y el centro de datos central o la solución en la nube. Aunque estos servidores ayudan en el procesamiento, siguen necesitando la transmisión de datos fuera del punto de recogida, lo que puede consumir un ancho de banda considerable y provocar latencia. La computación de borde distribuida permite que cada dispositivo de borde de la red recopile, almacene y procese los datos por sí mismo. A menudo no se requiere una conexión constante a la red, lo que permite que las operaciones continúen independientemente de la estabilidad de la conexión.
Infraestructura de borde
La infraestructura de borde engloba todos los componentes de red, dispositivos móviles conectados y puntos de acceso IoT dentro del sistema más amplio. Las soluciones exactas de hardware y software de computación de borde varían, y pueden incluir una gama de nodos y dispositivos de computación de borde:
También hay que tener en cuenta un componente de software. Por ejemplo, plataformas como Digi Remote Manager® permiten a las organizaciones supervisar y controlar el hardware en el perímetro, lo que las convierte en una parte necesaria de la ecuación.
Por ejemplo, Digi Remote Manager proporciona visibilidad de toda la red, acceso remoto, configuración de dispositivos y supervisión de la seguridad desde un "único panel de cristal". Además, esta solución proporciona alertas y notificaciones instantáneas desde el borde de la red, basadas en condiciones especificadas, y permite el acceso fuera de banda a los dispositivos de borde para la gestión remota.
Ventajas de Edge Computing
Son muchas las ventajas de la computación de borde que hacen que este enfoque sea valioso para una amplia gama de casos de uso. He aquí algunos ejemplos:
- Con IoT edge computing, las empresas industriales pueden supervisar activamente la producción, lo que les permite tomar decisiones operativas basadas en datos en tiempo real.
- Y en las aplicaciones de la Industria 4. 0, la computación de borde es crucial para el procesamiento en tiempo real en robótica y automatización de la fabricación.
- El procesamiento de datos en tiempo real crea oportunidades de intervención inmediata en la asistencia sanitaria cuando cambia el estado de un paciente, y garantiza que las empresas financieras puedan sacar provecho de los rápidos cambios en las condiciones del mercado.
- Las herramientas de Edge Computing y los dispositivos inteligentes permiten a las empresas de cualquier sector reducir la tensión de la red y el uso del ancho de banda. Junto con un ahorro de costes, esto reduce la exposición a posibles amenazas. Además, permite que las operaciones críticas continúen incluso si se pierden las conexiones a la nube, lo que permite que las aplicaciones y sistemas de edge computing respalden la continuidad del negocio.
A continuación se detallan algunas de las ventajas de las plataformas, el software, los servicios y la infraestructura de edge computing:
- Análisis de datos en tiempo real: El software y las soluciones Edge Computing eliminan los retrasos en el procesamiento. A su vez, las organizaciones pueden recibir información inmediata, lo que les permite tomar decisiones en tiempo real para mejorar la eficiencia, resolver problemas rápidamente o aprovechar breves oportunidades.
- Seguridad y privacidad: Dado que el procesamiento de borde requiere que se transmita menos información a través de las redes, se minimiza la exposición a las amenazas, ya que es posible que los datos confidenciales nunca tengan que cruzar Internet. Además, una cantidad significativa de datos no se almacena con un proveedor externo en la nube.
- Ancho de banda y eficiencia: Dado que los servicios de computación de borde realizan la computación, el análisis y la automatización en el borde, eso reduce el uso de recursos de red y ancho de banda y aumenta la eficiencia. Además, el menor uso de ancho de banda a menudo se traduce en un ahorro de costes, lo que permite a las organizaciones reducir las llamadas de servicio o evitar los excesos inesperados que pueden desencadenar cargos adicionales.
- Velocidad y latencia reducidas: La computación de borde permite una respuesta más rápida a los eventos locales. Con edge computing, la latencia puede reducirse habitualmente hasta casi cero. Además de beneficiar directamente a las organizaciones, la velocidad mejora la experiencia de las aplicaciones centradas en el usuario, como juegos, streaming y comunicaciones en tiempo real.
- Gestión remota: Las plataformas de gestión remota permiten a las organizaciones supervisar a distancia los dispositivos de borde desplegados, simplificando la gestión de dispositivos y redes. Estas plataformas centralizadas son una parte crucial de la ecuación, ya que garantizan la accesibilidad, la información y las notificaciones desde cualquier lugar a través de un ordenador de sobremesa o un dispositivo móvil.
- Escalabilidad: El despliegue de la infraestructura de borde admite la expansión de los dispositivos desplegados y la escalabilidad general, lo que permite a las organizaciones aumentar o añadir funcionalidad cuando sea necesario, y permite a los sistemas de computación de borde manejar cargas de datos cada vez mayores de un número creciente de dispositivos conectados.
- Contención de costes: La computación de borde puede ayudar a las organizaciones a reducir costes al reducir la necesidad de una amplia infraestructura en la nube. Además, el procesamiento y el almacenamiento localizados pueden ser más rentables, especialmente para las organizaciones que operan en entornos con recursos limitados.
- Sostenibilidad: Con la computación de borde, las empresas pueden reducir su huella de carbono y mejorar la sostenibilidad. Los dispositivos periféricos suelen funcionar con baterías de bajo consumo. La toma de decisiones en tiempo real que soportan también puede eliminar el despilfarro mediante la identificación de ineficiencias o el ajuste de procesos, y la capacidad de ampliar o reducir rápidamente puede mantener las operaciones en el tamaño adecuado de forma continua, garantizando un uso eficiente de la energía y los recursos.
- IA en el perímetro: La integración de la IA con productos y soluciones de computación periférica mejora las capacidades de los dispositivos IoT . Los dispositivos disponen de funciones avanzadas de procesamiento y análisis de datos, lo que permite obtener información más detallada, a menudo en tiempo real.
Soluciones de computación de borde
Para obtener una solución eficaz, las organizaciones deben adaptar su infraestructura de vanguardia al sector y al caso de uso de la organización. De este modo se garantiza que la solución satisfaga las necesidades, prioridades y dificultades específicas con un enfoque específico.
Las soluciones integrales de edge computing también permiten a las organizaciones aprovechar las tecnologías de vanguardia para mejorar los resultados. La incorporación de conectividad celular 5G reduce la latencia y mejora la conectividad de los dispositivos periféricos en toda la red. La implementación de IA y aprendizaje automático puede permitir el procesamiento avanzado de datos en tiempo real a nivel de dispositivo, favoreciendo la velocidad y la agilidad cuando más importa.
Informática de borde para empresas
La informática empresarial tradicional depende en gran medida de la transmisión de datos, que se crean en puntos finales como los ordenadores de los usuarios antes de transferirse a servidores centralizados. La computación de borde empresarial utiliza la potencia de cálculo de los dispositivos de toda la red, lo que reduce la presión sobre los recursos de red, reduce los costes de datos, mejora la fiabilidad y aumenta la velocidad.
Con soluciones de computación de borde empresarial a medida, las organizaciones pueden crear un ecosistema personalizado para soportar la escalabilidad y mantener la asequibilidad al tiempo que mejoran la eficiencia.
Informática de borde industrial
La computación de borde industrial proporciona a los dispositivos de borde, los sistemas de automatización, la maquinaria y la robótica la potencia de procesamiento de alta velocidad que necesitan y da a las organizaciones acceso a análisis en tiempo real que facilitan la toma rápida de decisiones en entornos vertiginosos y en constante cambio. Los dispositivos IIoT Edge (Internet industrial de las cosas) diseñados para este sector suelen ser resistentes -lo que garantiza que puedan soportar desafíos ambientales como temperaturas extremas y seguir funcionando de forma óptima- y tienen una alta fiabilidad con conmutación por error y redundancia integradas.

Aplicaciones y casos de uso de Edge Computing
Hoy en día, las aplicaciones de edge computing ya se utilizan a nuestro alrededor, desde los lectores de huellas dactilares de los smartphones hasta el control del tráfico en tiempo real en los cruces. Veamos algunos ejemplos verticales de edge computing.
Fabricación
En la industria manufacturera, las soluciones de computación de borde permiten la automatización de la fabricación, la robótica y el mantenimiento predictivo. IoT edge devices in the Industry 4.0 paradigm can perform factory assemblies, rapidly scale production up or down based on demand, and improve production speed and accuracy - freeing up personnel to handle engineering, technician, and management tasks.
Además, las cámaras de vídeo y los dispositivos de vanguardia de IoT pueden detectar anomalías en la producción y retirar piezas que no cumplan las especificaciones. Pueden supervisar la eficiencia de la producción y comparar los datos con los plazos históricos para apoyar las reparaciones proactivas. Y pueden utilizar diagnósticos adaptativos para alertar a los técnicos sobre el origen potencial de los problemas y acelerar la resolución de problemas. IoT y la computación de borde están impulsando hoy una transformación digital completa en la industria manufacturera, permitiendo a los fabricantes construir fábricas inteligentes, utilizando dispositivos de borde para apoyar la automatización industrial y el mantenimiento predictivo.
Venta al por menor
En el sector minorista, el procesamiento de datos en el perímetro permite realizar análisis en tiempo real dentro de la tienda, lo que permite a los minoristas adaptarse rápidamente a las condiciones cambiantes. Los dispositivos IoT pueden automatizar la gestión del inventario, alertando a los minoristas cuando las cantidades de productos específicos caen por debajo de los umbrales establecidos. La computación de borde también puede personalizar las experiencias de compra de los clientes, utilizando información basada en datos para personalizar las recomendaciones a los clientes y realizar ajustes dinámicos de precios para aumentar las ventas de productos y servicios.
Sanidad
El Edge Computing permite procesar en tiempo real los datos generados por dispositivos médicos, wearables y sensores. Esto es crucial en situaciones sanitarias que requieren decisiones y respuestas inmediatas, como cambios repentinos en las constantes vitales del paciente o situaciones médicas de emergencia.
Los dispositivos médicos portátiles pueden almacenar información sobre la frecuencia cardíaca, la temperatura, el nivel de azúcar en sangre y otras métricas que luego pueden enviar notificaciones importantes al paciente o al médico y proporcionar recordatorios inteligentes para la medicación. Además, el edge computing permite a las organizaciones sanitarias mejorar la seguridad y la privacidad, limitando la transmisión de información sensible y protegida del paciente. La computación de borde también puede potenciar las capacidades de las soluciones de telemedicina, y los dispositivos IoT pueden realizar análisis rápidos de datos durante procedimientos médicos críticos, mejorando la experiencia y los resultados de los pacientes.
Transporte
El edge computing desempeña un papel crucial en la transformación de los sistemas de transporte, ofreciendo diversos usos y ventajas para mejorar la eficiencia, la seguridad y el rendimiento general. Estas son algunas de las principales aplicaciones y ventajas del edge computing en el transporte:
- Vehículos autónomos: La computación de borde permite a los vehículos autónomos analizar datos en tiempo real y tomar medidas rápidas para responder a las condiciones cambiantes, leer y responder a las señales de tráfico y mantener la seguridad.
- Gestión del tráfico en tiempo real y encaminamiento del transporte público: IoT y la computación periférica permiten a las ciudades inteligentes gestionar el tráfico de forma proactiva adaptando los semáforos a las condiciones cambiantes de las carreteras. En la actualidad, el procesamiento de señales de tránsito permite a los autobuses circular con mayor fluidez por las congestionadas calles de la ciudad para garantizar que los pasajeros del transporte público lleguen a tiempo a sus destinos.
- Vehículos de emergencia: Con sofisticados routers celulares a bordo, los vehículos policiales aprovechan cada vez más el procesamiento edge para gestionar localmente los datos de los dispositivos y periféricos de a bordo, así como de las cámaras corporales y los dispositivos de comunicación, con el fin de mejorar los tiempos de respuesta.
- Logística: Las organizaciones de envío y recepción se benefician de IoT y la computación de borde en el seguimiento de activos y la supervisión de vehículos y carga.
Ciudades inteligentes
Con la computación de borde, las ciudades inteligentes de hoy pueden aumentar la sostenibilidad gestionando de forma proactiva el uso de la energía en las infraestructuras, incluidos los servicios públicos, el alumbrado público, la gestión del agua y las aguas residuales y los sistemas de movilidad urbana. Del mismo modo, las soluciones edge pueden mantener conectadas a las organizaciones de seguridad pública, garantizando la disponibilidad de datos en tiempo real durante emergencias, incluidas las catástrofes naturales. IoT y edge computing también apoyan la gestión de residuos, la compactación de la basura y el enrutamiento inteligente de los vehículos de saneamiento. Además, los dispositivos de IoT permiten a las ciudades controlar los edificios y vehículos de propiedad pública, mejorando la seguridad y garantizando un uso adecuado.
Tecnología Edge Computing
La tecnología Edge Computing aúna la potencia de redes más rápidas, dispositivos edge inteligentes y mejoras en la programación, lo que permite realizar cálculos y gestionar datos en el extremo de la red. Veamos los componentes de un modelo de edge computing.
Sistemas Edge
Los sistemas periféricos son soluciones integrales que proporcionan a las organizaciones todos los componentes necesarios para procesar datos en el perímetro. Normalmente, hay cuatro componentes principales: dispositivos móviles y IoT , conectividad de red, soluciones de almacenamiento y plataformas de gestión de sistemas. Los dispositivos recopilan y procesan los datos en el perímetro, mientras que las redes permiten transmitir los datos designados a soluciones de almacenamiento, como servidores o almacenamiento en la nube. Las plataformas de gestión de sistemas supervisan el sistema periférico y controlan los dispositivos, la velocidad de conexión y otros aspectos.
He aquí algunos ejemplos de sistemas Digi edge:
Dispositivos Edge
Los dispositivos periféricos son soluciones de hardware informático especializadas que soportan el procesamiento de datos en el perímetro. Además, pueden soportar diversas necesidades de conectividad, garantizando que cualquier transmisión de datos que deba producirse pueda hacerlo con una latencia limitada y una fiabilidad adecuada. Algunos dispositivos de borde comunes incluyen:
Plataformas Edge
La computación de borde requiere plataformas de software para apoyar y gestionar el sistema global. Digi Remote Manager es un ejemplo de solución integral. Con Digi Remote Manager, la configuración y el despliegue de dispositivos están centralizados. Además, las organizaciones pueden configurar actualizaciones automáticas de los dispositivos, supervisar la seguridad y recibir alertas instantáneas. También se dispone de opciones de seguridad avanzadas, como VPN.
- Digi Remote Manager
- Microsoft Azure IoT Edge
- Nube distribuida Google Edge
Productos y servicios Edge Computing
Digi es un proveedor líder de productos y servicios de computación de borde, que ofrece soluciones de alto rendimiento adaptadas a sectores específicos. Estas soluciones integrales proporcionan los dispositivos críticos, el software y los servicios de apoyo que las organizaciones necesitan para realizar la transición a la infraestructura de borde sin problemas.
A continuación se ofrece una visión general de los distintos productos y servicios de Digi Edge Computing y de cómo pueden beneficiar a su organización.
Hardware Edge Computing
Las soluciones de hardware de edge computing de Digi están diseñadas para satisfacer las necesidades de las organizaciones que buscan sacar el máximo partido de su inversión en IoT , garantizando que disponen de la capacidad informática, la seguridad y la conectividad fiable para agilizar las operaciones, mejorar la seguridad, automatizar los procesos y dar soporte a capacidades avanzadas como la IA. Desde sistemas integrados hasta routers celulares, las soluciones de Digi permiten la computación avanzada de borde en todas las industrias. Entre ellas se incluyen:

Fichas Edge
Los chips Edge son componentes integrados en módulos de sistema, diseñados para satisfacer los requisitos más avanzados de las aplicaciones de IoT en los ámbitos médico, industrial y del transporte. Estos SOM admiten IA en el perímetro, lo que mejora las capacidades de los dispositivos de perímetro y admite el análisis de datos en tiempo real para la toma rápida de decisiones y los ajustes operativos. Digi integra los procesadores de aplicaciones más potentes del sector, de fabricantes como NXP y STMicroelectronics, con soluciones listas para el diseño que permiten a las organizaciones de cualquier sector beneficiarse de estas tecnologías de vanguardia con un rápido plazo de comercialización.

Servidores Edge
Los servidores periféricos se encuentran fuera del centro de datos central o de la solución en la nube, por lo que están más cerca de los usuarios finales y de los dispositivos que generan datos. La incorporación de servidores de borde mejora la capacidad de computación al tiempo que reduce drásticamente la latencia. Además, los servidores de borde están conectados a redes internas, lo que elimina la necesidad de transferir datos a través de Internet y los hace más seguros.
Digi ofrece una serie de opciones de servidor diseñadas para satisfacer una gran variedad de necesidades y casos de uso, entre las que se incluyen:
Nodos Edge Computing
Los nodos de computación de borde son máquinas físicas o virtuales situadas en el borde de una red e incluyen la gama de dispositivos de borde y servidores de borde de los que hemos hablado. Normalmente, funcionan como routers, pasarelas, procesadores de aplicaciones o servidores de borde, permitiendo a los dispositivos IoT comunicarse entre redes, realizar tareas de computación de borde (en el caso de los dispositivos inteligentes) y transferir datos hacia y desde otros dispositivos de borde o un servidor de borde intermediario conectado a la nube. Además, pueden ayudar potencialmente en la recopilación y el análisis de datos, así como ejecutar aplicaciones en contenedores con las que los dispositivos IoT necesitan interactuar como parte de sus operaciones.
Los nodos de computación de borde de Digi -que incluyen todos los dispositivos de hardware de borde enumerados anteriormente- son soluciones flexibles, programables, fáciles de desplegar y gestionar que pueden configurarse para satisfacer las necesidades de una amplia gama de aplicaciones de computación de borde. Además, nuestras soluciones dan prioridad a la seguridad, garantizando la protección de su entorno.
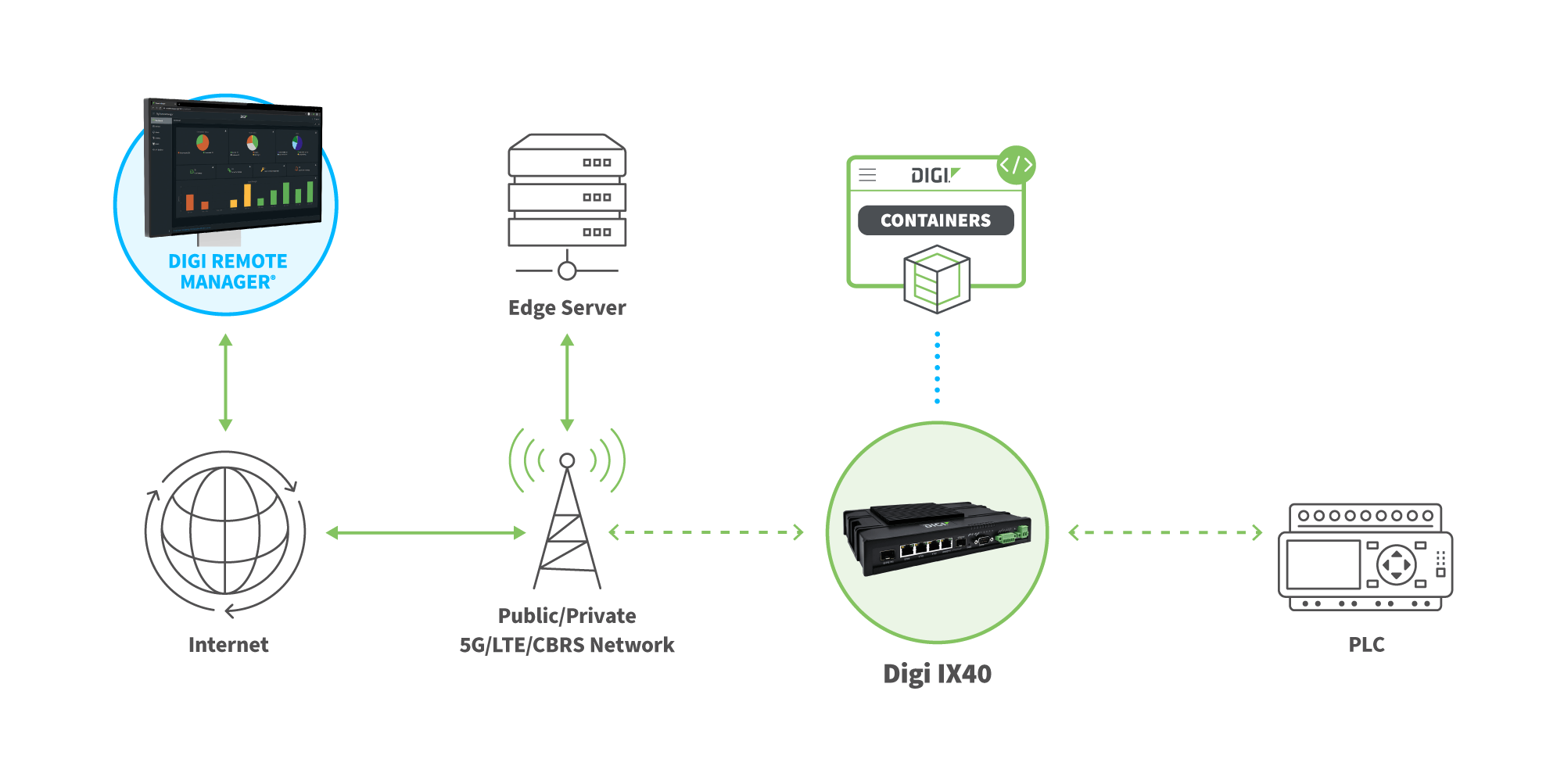
Software Edge Computing
El software Edge Computing simplifica la gestión de una red inteligente. Además de proporcionar supervisión Digi Remote Manager agiliza la configuración e implantación de dispositivos. Además, admite actualizaciones masivas de firmware y software a lo largo del ciclo de vida del producto para simplificar la seguridad y el cumplimiento normativo, y proporciona alertas en tiempo real sobre las condiciones de los dispositivos y el estado de la red.
Servicios de Edge Computing
IoT y la computación de borde ofrecen enormes ventajas a medida que las organizaciones tratan hoy de aprovechar al máximo sus plantillas, recursos y presupuestos para optimizar sus operaciones, sus servicios técnicos y de TI y su seguridad. Pero emprender estas iniciativas puede añadir complejidad a los objetivos de la organización durante la planificación, el desarrollo y el despliegue, así como la gestión continua de dicho despliegue.
Digi dispone de una completa gama de servicios para apoyar las iniciativas de organizaciones de todos los sectores, tanto si están diseñando y construyendo productos con sistemas integrados, desplegando IoT y dispositivos informáticos en el borde de la red, como actualizando su infraestructura existente para mejorar las operaciones:
- Servicios de diseño de Digi Wireless: Este equipo de ingenieros de gran talento puede ayudar a los fabricantes de equipos originales a crear prototipos, desarrollar, certificar, gestionar y llevar productos al mercado.
- Servicios profesionales de Digi: Este equipo de expertos puede proporcionarle una amplia gama de asistencia a medida que planifica su despliegue, desde estudios del emplazamiento, así como la adquisición y el despliegue, hasta la creación de scripts y la programación, pasando por el apoyo a la gestión continua de la red desplegada.
- Servicios de conectividad de Digi: El equipo de servicios de conectividad de Digi ayuda a los fabricantes de equipos originales que desarrollan productos con módulos Digi XBee Cellular a configurar rápidamente planes de datos, lo que convierte en un proceso sencillo y cómodo añadir conectividad celular y crear redes inalámbricas.
- Soporte técnico de Digi: Este equipo de profesionales puede ayudar con la solución de problemas técnicos y la resolución de problemas con una gama de opciones de soporte, incluidos los contratos de soporte prioritario para despliegues de misión crítica.
Digi Internacional: Líderes en soluciones Edge Computing
En la era digital actual, las soluciones de computación de borde ofrecen funcionalidades críticas a la vez que agilizan las operaciones. El procesamiento de datos en origen permite la automatización, el análisis en tiempo real y la toma rápida de decisiones en entornos en constante cambio. En última instancia, los sistemas periféricos garantizan una agilidad y escalabilidad constantes, además de mejorar la potencia de cálculo y facilitar la integración e implantación de tecnologías de vanguardia como la IA y el aprendizaje automático.
Digi ofrece soluciones de vanguardia diseñadas para satisfacer las necesidades de diversos sectores, desde la automatización de la fabricación hasta la sanidad, el comercio minorista, el transporte y el sector público, entre otros. Nuestras soluciones se diseñan teniendo en cuenta la solidez y el cumplimiento de normativas, lo que garantiza su funcionamiento óptimo en condiciones difíciles y proporciona mecanismos de seguridad críticos para salvaguardar los datos.